
Disaster Recovery is a topic that comes up in most of my interactions with customers.
In my 3+ years in the VMware Cloud team, my general observations are:
- Some customers’ DR strategy is limited to copying data to offsite tapes… but most large enterprise customers I talk to have a secondary or tertiary site they use for DR and use some kind of data replication between a primary site and its destination.
- The DR site is usually equipped with some of the older hardware that is no longer used by the ‘primary’ site. The DR site is sometimes used for testing but is also often a ‘ghost’ site. Most customers don’t like having a site only there “just in case” and would ideally like to shut it down.
- Many customers would like to have a disaster recovery strategy per application where they could apply different Recovery Time Objectives and Recovery Point Objectives, depending on the criticality of the application. For example, one of my customers had the following RPO objectives:
- T0 – immediate recovery
- T1 – 4hrs
- T2 – 4 to 24hrs
- T3 – 24hrs
- T4 – no recovery/reasonable endeavours
Overall, many customers really like the idea of using the Cloud as a disaster recovery site. And VMC was a pretty obvious use case for this.
Until VMware acquired a company called Datrium, there was only one option for cloud-hosted DR – VMware Site Recovery – which leverages vSphere Replication, VMware Site Recovery Manager and a VMC as a ‘hot-standby site’: meaning customers needed to have a running VMC instance at any time where vSphere Replication could copy the data of the live vCenter across to. In many cases, it meant VMC as a DR site was wasteful (that’s a lot of compute sitting there idle).
And if you look back at my customer’s RPO objectives above, most apps don’t need the sub-30 minutes RPO you get with VMware Site Recovery.
Once Datrium was integrated with VMC, we launched a solution called VMware Cloud Disaster Recovery, which offers a 4-hour RPO option at a much affordable pricepoint.
In summary: for critical workloads, use VMware Site Recovery. For everything else that doesn’t need the urgent RPO, use VMware Cloud Disaster Recovery.
My colleague Simon published a great summary of the options here.
Demo
I asked my teammate Eskander to walk us through the product. The first video below shows the console and the installation. Really straight-forward to set up.
Pretty easy, right? Log onto the console:
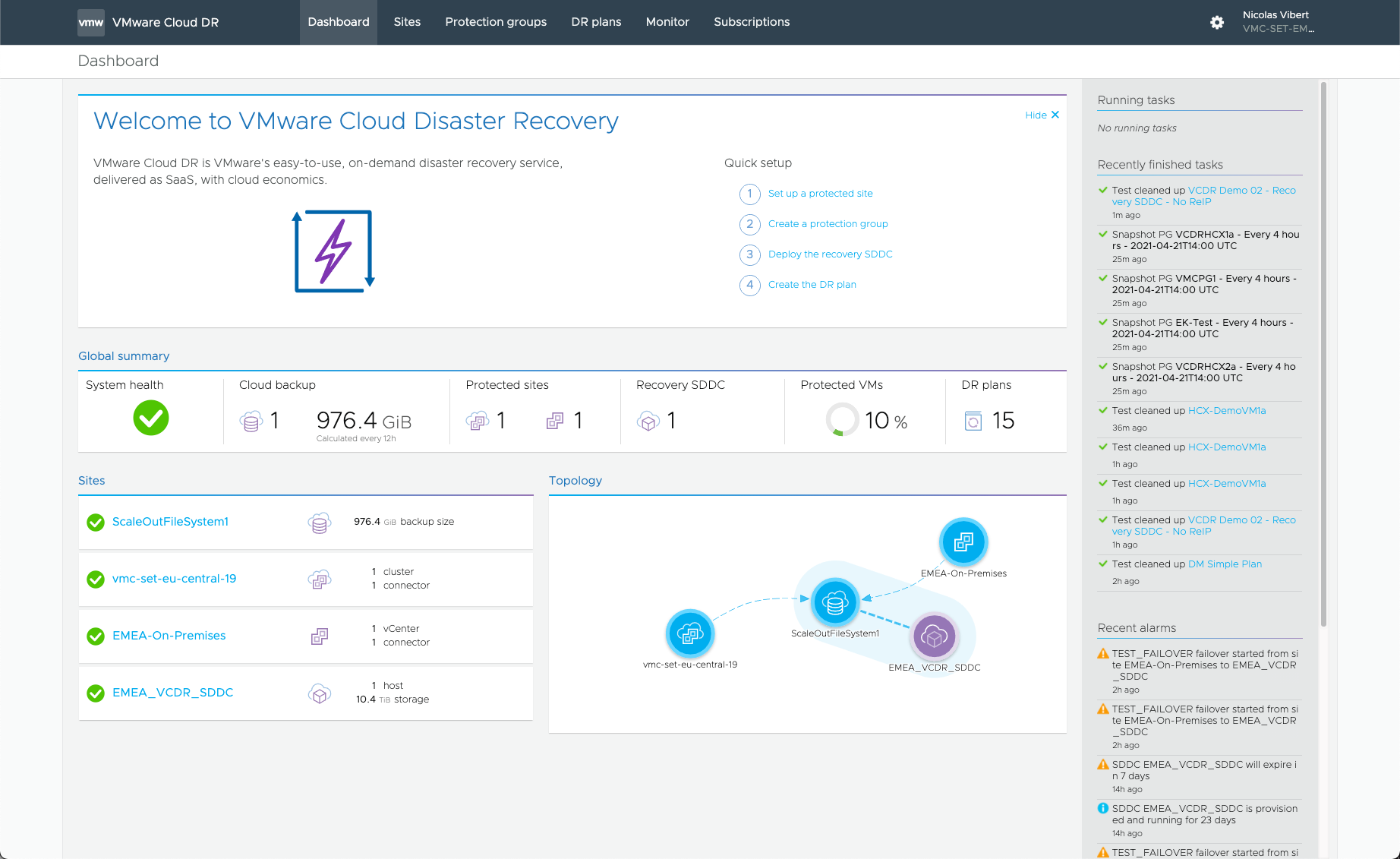
Add a protected site: we can now protect a VMC instance to recover to a different VMC instance but most customers will select the “on-prem vSphere” option.

Once that’s done, we just need to sync up the protected site with the Cloud backup by installing a connector appliance.
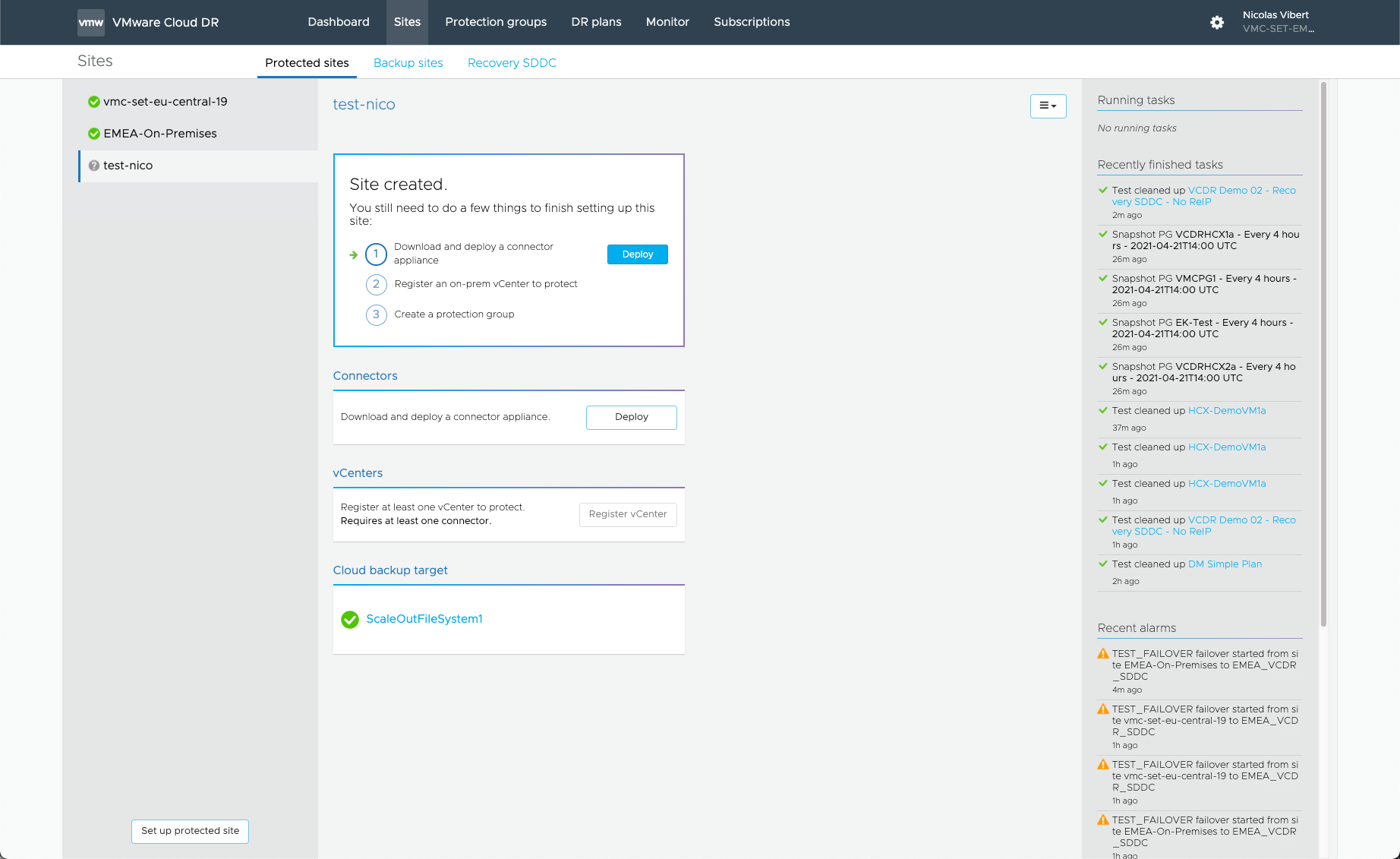
Pretty clear and easy to do (obviously, remember the FW requirements).

Then, we just have to build a protection group. Like you can see here, I am creating one based on either a vSphere tag or based on the name of the VM:
You can build different protection groups and different protection policies (how often we save the data) for each application requirements.
Now, let’s go back to Eskander as he walks us through the recovery and setting up DR plans.
Again, it’s pretty straight-forward. You have 2 options when you set up your DR plan. Either you point to an existing SDDC (pilot light site) with the “Existing recovery SDDC” option or you can ask VCDR to deploy an SDDC on-demand. As deploying an SDDC takes 90 minutes, it does add up to the recovery time but it’s a cheaper option as you don’t need the “pilot light” site.

If you have an existing recovery SDDC like I am showing below, you can prepare everything – how each folder, resources, networks, etc… would map to each. You can also run a script from a VM. That’s going to be handy later.

As you heard in the video, what we don’t have natively within the product yet is the ability to deploy a prepared networks, NAT and security rules configuration and that’s something very commonly asked by customers.
Thankfully, Patrick and I (with the help of Will and Shashi) released a Fling called SDDC Import/Export for VMware Cloud on AWS to address this type of requirements.
I wrote a long post about it here .
Patrick, Eskander and I discuss how we would use the Fling to help customers with restoring their networking configuration to the recovery site:
In a nutshell, what customers can do is:
- Deploy a test recovery SDDC and prepare it with the right networking configuration
- Save the configuration, with the export function of the Fling
- Tear down the test recovery SDDC
- Restore the SDDC during the live recovery event and either run the script manually from a VM outside the cloud or from a Script VM (as explained in these docs).
The video below shows how easy it is to save/export the configuration.
It’s just a single command to export the config. And vice-versa – it’s the same stuff to import it, with the “-o import”, instead of “-o export”.
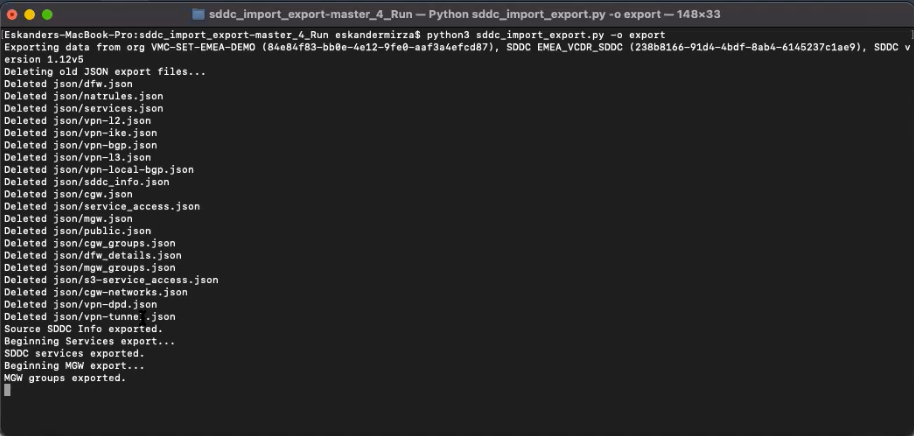
In summary, it’s pretty easy with VMware Cloud Disaster Recovery to start protecting your site, to set up protection policies based on your application requirements and to invoke DR when needed. With the use of the SDDC Import/Export fling, the last piece – the networking config – can be restored with a single command.
Thanks for reading/watching this post!

One thought on “VMware Cloud Disaster Recovery – Walkthrough and Integration with the SDDC Import/Export Fling”